
Baza mezuro de la sukceso de Esperanto estas la nombro de esperantaj parolantoj. Ĉar Esperanto estas la plej populara artefarita lingvo, tiu nombro ankaŭ mezuras la sukceson kaj potencialon de artefaritaj lingvoj ĝenerale. Ju pli granda la nombro estas, des pli interesa estas eklernado por homoj, kiuj konsideras Esperanton. Tial, la nombro estas kaŭzo de multe da polemiko. En ĉi tiu afiŝo mi verkas superrigardon pri diversaj taksoj kaj analizas ilin. En 2016 mi mem taksis la nombron de esperantistoj, kaj mi ankaŭ iomete defendas la takson ĉi tie.
Estas malfacile trovi la nombron de esperantaj parolantoj en la mondo. La unua problemo estas ‘kio estas parolanto?’. En 1996 Jouko Lindstedt proponis, ke
- 1,000 parolas Esperanton denaske
- 10,000 parolas Esperanton flue
- 100,000 kapablas komuniki per Esperanto
- 1,000,000 scias elementojn de Esperanto
Li diris tiel por montri, ke la nombro de esperantaj parolantaj dependas de la nivelo de la parolado. Malofte, Esperanto aperas en lernejoj aŭ estas denaska lingvo. Tial, multaj homoj ne lernas Esperanton bone, kaj la nivelo de la parolado multe varias kompare al aliaj lingvoj, kiuj havas bazon de denaskaj parolantoj.
Mi trovis 10 malsamajn taksojn surrete kaj mi arigis ilin en 4 kategorioj.
Diveno
La unua kategorio enhavas taksojn, kiuj ne devenas de konkreta dateno. Pere intuicio, la verkinto elektis verŝajnajn nombrojn de parolantoj. Ni jam vidis la divenojn de Lindstedt(1996). Poste, Marko Cramer(2016) divenis, ke
| Singarda takso | Kuraĝa takso | |
|---|---|---|
| Active or passive >10 hours a year, | 30,000-2,000,000 | 120,000-500,000 |
| Active or passive >100 hours a year | 3,000-200,000 | 12,000-50,000 |
| Active >10 hours a year | 5,000-100,000 | 15,000-35,000 |
| Active >100 hours a year | 1,000-20,000 | 3,000-7,000 |
Aliaj divenoj estas
- Simon Payne(2000) divenis, ke estis 4,000-20,000 fluaj parolantoj.
- Ziko van Dijk(2003) divenis ke estis malpli ol 40,000-50,000 parolantoj de Esperanto en Esperanto Sen Mitoj.
Estas malfacile analizi la taksojn plie, ĉar ilin ne subtenas datenoj kaj supozoj. Poste, mi komparos ilin plie.
Skali populajn censojn
Okazis, ke iu sisteme nombris la nombron de esperantaj parolantoj en limigita areo. Por atingi la mondan nombron de esperantaj parolantoj, oni povas skali tiun lokan nombron. Oni povus naive provi
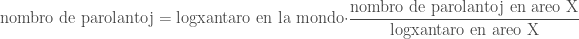
Bedaŭrinde, tio ne bone funkcias, ĉar la loĝantaro ne estas bona indiko de esperantaj parolantoj. Do, ni anstataŭigu la loĝantaron per alia indiko
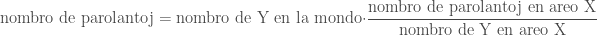
Multaj nuntempaj taksoj uzis tiun metodon.
| Verkinto | X: Censa areo | Y: ligila indiko | Nombro |
|---|---|---|---|
| Lu Wunsch-Rolshoven(2009) | Litovio(2001) | Membroj de UEA(2001) | 160,000 |
| Lu Wunsch-Rolshoven(2009) | Hungario(2001) | Membroj de UEA(2001) | 300,000 |
| Andreas Kück(2005) | Parto de norda Germanujo^1 (2005) | UEA deligitoj laŭ baza frekvenco^2 (2001) | 80,000 |
| Jiri Lebl(2016) | Hungario(2011) | Esperantistoj en esperantujo.directory | 276,000, see ^3 |
| Jiri Lebel(2016) | Litovio(2011) | Esperantistoj en esperantujo.directory | 192,000 |
| Jiri Lebel(2016) | Estonio(2011) | Esperantistoj en esperantujo.directory | 233,000 |
| Jiri Lebel(2016) | Rusio(2010) | Esperantistoj en esperantujo.directory | 34,000 |
| Jiri Lebel(2016) | Novzelando(2006) | Esperantistoj en esperantujo.directory | 34,000 |
| Svend V. Nielsen(2016) | Averaĝo de: Litovio(2011), Estonio(2011), Novzelando(2006), Rusio(2010)^4 | Membroj de: UEA, lernu.net, edukado.net, Pasporta Servo, esperantujo.directory kaj la naciaj asociaj^5 | 62,983.9 [31,000-183,000] |
- ^1: Andreas Kück nombris la esperantistojn en sia loka regiono. Inter 1,206,000 homoj estis 30 esperantistoj.
- ^2: Anstataŭ uzi la veran nombron de UEA deligitoj en sia loka regiono, AK uzis la atenditan nombron de UEA deligitoj laŭ la averaĝa frekvenco de UEA deligitoj en Eŭropo, Brazilo, Chinio, Japanujo, Sud-Koreujo, Usono, Kanado kaj Kubo.
- ^3: Jiri Lebl originale uzis la nombrojn 10,000 kaj 35,000 esperantaj parolantoj en Hungario. 10,000 estis diveno de la nombro de parolantoj en hipoteza, nuntempa popula censo. 35,000 estis la nombro de homoj, kiuj ekzameniĝis en Esperanto en lernejo. Mi anstataŭigis tiujn nombrojn per 8397, kiu estas la fakta, censa nombro de parolantoj.
- ^4: Mi uzis la averaĝon de la kvantoj
per la kvar mencitaj censoj.
- ^5: Mi konstruis novan variablon bazite sur la ses mencitaj variabloj.
Evidente, estas multaj eblaj elektoj de X kaj Y, sed kiuj elektoj estas la plej bona?
- Ju pli granda korelacio inter nombro de parolantoj kaj Y,
- Ju pli la takso de la frakcio,
des pli bona estas la takso. Se korelacio estus 1 (la plej grande ebla korelacio), la takso de la frakcio ne dependus de X. Se la frakcio ne dependus de X, ni ne bezonus, ke X kaj Y estu korelaciaj. En ambaŭ hipotezaj situacioj, la takso estus la vera nombro. Bedaŭrinde, la du situacioj ne veras, do ni konsideru kiom bone ili veras:
Komparo de korelacioj
Ni povas taksi la korelaciojn per la kvin populaj censoj Litovio(2011), Estonio(2011), Novzelando(2006), Rusio(2010), kaj Hungario(2011).


Ĉiu Y variablo havas malbonan korelacion. La kaŭzo estas Hungario – vidu ekzemple la subajn grafikikaĵojn, en kiuj Hungario estas forigita.


La esperanta situacio en Hungario estas nekutima ĉar ili instruas Esperanton en la ŝtataj lernejoj. Tio kaj la grafikaĵoj sugestas, ke oni devus ne uzi Hungarion por monda eksterpolado. La grafikaĵoj ne diras kiun metodon pli bonas. Neniu ŝajnas malĝusta. La SVN-modelo uzas informaĵojn de ses variabloj, kaj la aliaj uzas nur unu variablon. Do oni atendus, ke Y en la SVN-modelo havas malpli da vario kaj tial pli da korelacio kun la nombro de parolantoj. La AK-modelo ankaŭ atingas malgrandan varion en la Y-variablo sed pere granda supozo. Ĝi supozas, ke la denseco de UEA deligitoj nur havas du malsamajn nivelojn; unu por [Eŭropo, Brazilo, Chinio, Japanujo, Sud-Koreujo, Usono, Kanado kaj Kubo] kaj unu por la resto. Pro tio la sistema devio(=”bias” en la angla) estas granda. Tial oni ne atendus grandan korelacion inter la Y variablo en la AK-modelo kaj la nombro de parolantoj.
La areo X
La SVN-metodo uzas kelkajn censojn por taksi unu totalan nombron, la LW kaj JL modeloj taksas nombron por ĉiu censo, kaj la AK modelo uzas nur unu censon. Estas prefere nur havi unu nombron anstataŭ kelkaj nombroj. La metodo de kunigado de la diversaj censoj en la SVN-metodo estas simpla averaĝo de la apartaj taksoj. Do se ni uzas la metodon sur la JL-taksoj (kun Hungario)
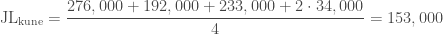
Ekzistas ankaŭ aliaj metodoj de kunigado. Oni povas kunigi ĉiujn regionojn en unu regionegon, sed tiu metodo estas pli vundebla per ekstremaj censoj. Ekstremaj punktoj estas verŝajnaj ĉar la censoj ne estas identaj. Ili uzas malsamajn demandojn, la landoj estas malsamaj kaj la fido al la registraro malsamas kaj tiel plu. Tial mi pensas de la kuniga metodo de SVN taŭgas.
La populaj censoj
Mi ne povis trovi legeblajn informaĵojn pri la rusa censo(se vi komprenas la rusan lingvon, kaj volas helpi min, la informo estas tie). Ĝenerale la elcento de la populo, kiu respondis estis tre alta.




La novzelanda kaj hungara demando celas la kapablon paroli esperante, kaj la litova kaj estona celas kaj paroladon kaj legadon. Ni atendus, ke la litova censo kaj la estona censo atingis relative pli da esperantaj homoj. Tio eblas, sed ne estas klare laŭ la Y-varibloj en la SVN-, AK-, LW- kaj JL-modeloj.
Multaj esperantistoj dubis pri la kvaliteco de la rusa censo (Vidu la apendikson), kaj intervjuinto diris, ke multege de la dateno estis forĝita, ĉar la rusanoj ne laŭleĝe devis respondi. Tamen la signoj de fuŝado nur estas anekdota, kaj la censa nombro de esperantaj parolantoj, 992, ne estas strange kompare al la projektataj nombroj laŭ la kvar modeloj. Kiel la rusa censo, la novzelanda censo ankaŭ atingis malgrandan nombron de parolantoj kompare al la kvar modeloj. En Novzelando la loĝantoj devis respondi laŭleĝe, do la novzelanda censa nombro de parolantoj verŝajne ne estas tro malgranda. Konklude, estas signoj de problemoj en la rusa censo, sed ne estas fortaj signoj kiuj indikas, ke la efiko gravas. Do la rusa censo ne devas esti forigita.
Diskuto
La aro de landoj, en kiuj estis popula censo pri Esperanto, ne estas tute kutima landaro. Ili ekzemple ĉiuj havas relative multajn esperantistojn kaj esperantajn komunumojn. En multaj partoj de la mondo ne ekzistas esperantaj komunomoj. Eblas, ke la rilato inter la Y-variablo kaj nombro de parolantoj en lando dependas de la lokaj komunomoj aŭ aliaj faktoroj. Statistikaĵoj ĉiam estas vundebla per manko de dateno, sed en ĉi tiu situacio, mankaj datenoj potenciale gravus multe.
La rilatumo inter la Y-variabloj kaj la populaj censoj ne estas bonege. Tion ankaŭ montras la grandan konfidentan intervalon, [31,000-183,000]. Por atingi pli preciza takso necesas aŭ pli bona Y-variablo aŭ pli bonaj populaj censoj. La populaj censoj estas tre valora dateno, ĉar ili estas grandaj, neutralaj kaj sistemaj, sed ili povus esti malsimilaj pro malsamaj metodoj. Oni ankaŭ povas trovi Y-variablon kiu pli bone rilatas al la populaj censoj.
Se ni akceptas la aron de landoj kun censoj, la konfidentan intervalon tamen estas ĝusta.
Skali hazardajn populajn censojn
La takso
estus perfekta, se la takso de la frakcio,
- Dividi la mondon en aron de multaj regionoj.
- Eltiri n hazardajn regionojn el la aro.
- Konstrui la areon X konsistante de la n eltiritaj regionoj.
- Difini Y=loĝanto
- Uzi la formulon supran.
Kompreneble, la takso ankoraŭ dependas de la eltirita areo, X, sed ne multe. La takso havas nenion sisteman devion danke al la hazardeco. Ju pli da eltiritaj regionoj, des pli bona estas la takso. Tamen estas granda problemo; oni bezonus la nombron de parolantoj en areo X. Necesus fari tutan novan censon. Sidney Culbert(1989) provis fari tion dum 30 jaroj (1958-1988) kaj li finfine taksis 2,000,000 parolantojn. La difino de parolanto estis L3, kiu similas al la niveloj en la censaj demandoj. Li faris tion por la leksiko World’s Almanac, kaj li neniam publikigis la metodon aŭ sian datenaron. Ni nur havas unu leteron(1989) en kiu Culbert rankontas pri sia laboro, kaj unu retpoŝton(1996) en kiu David Wolff rakontas.
Culbert diris, ke li faris Partigita Hazarda Eltirado(= Stratified Simple Random Sampling en la angla). Tio signifas, ke li partigis la mondon en partojn, kaj taksis la nombrojn de parolantoj en ĉiu parto per Simpla Hazarda Eltirado. Tiel Culbert povis eltiri regionojn en la mondpartoj kiuj enhavas multe da esperantaj parolantoj pli ofte ol la regionoj en la aliaj mondpartoj. La fina takso ankoraŭ ne havus sisteman devion kaj ĝi eĉ havus malpli da vario.
Laŭ mia kompreno, Culbert nombris parolantoj en regiono en du manieroj. Unu estis profunda serĉado en kiu li legis malnovajn adresarajn librojn. Ne klaras ĉu li ankaŭ intervjuis supozajn parolantojn por sciigi ĉu ili atingis nivelon L3. La alia maniero estis intervjui kelkajn esperantistojn en regiono kaj iel kunigi iliajn taksojn de la nombro de parolantoj en ilia regiono. Li uzis ambaŭ manierojn en kelkaj eŭropaj regionoj por sciigi la rilaton inter la du manieroj. La regionoj produktis similajn nombrojn, do Culbert sekvante nur uzis la duan manieron – aŭ eble li uzis miksadon de la du manieroj. La letero ne estas klara. La kunigada metodo povus esti la mediano (lia letero denove ne estas klara).
La plano de Culbert povas teorie funkcii bonege, sed mi dubas pri la realigo.
- Dum la periodo 1959-1989 multaj mondpartoj estis neatingeblaj. Culbert ekzemple skribas, ke li devis viziti Alĝerion kaj DDR, sed ne faris tion pro la politika situacio. Ideale, li nur taksus la nombron de esperantistoj en la atingebla mondo. Sekvante li povus uzi singardajn supozojn por la neatingebla mondo. Culbert skribis ke li vizitis kvin kontinentojn, sed eble li nur vizitis facilajn lokojn, kie li jam povis trovi lokajn esperantistojn. Mi volas vidi la liston da vizitaj regionoj kaj la liston da eblaj regionoj.
- La nombrado en eltirita regiono ŝajnas malsistema. En la unua, profunda maniero: Kiel Culbert determinis ĉu parolanto parolis Esperanton je nivelo L3? Kaj kiel li trovis la parolantojn? Ni ne scias ĉu li daŭre serĉis kaj mallevigis la L3-nivelon ĝis sufiĉe da parolantoj estis trovitaj. En la dua, intervjua maniero: Kiom da esperantistoj li intervjuis? Kiel li elektis tiujn intervjuitojn? Se li nur intervjuis homojn, kial necesis viziti la lokon? Ĉu li mem ankaŭ serĉis lokajn parolantojn surloke? Eble Culbert nur uzis la kolektitajn datenojn por gvidi sin diveni la regionan nombron.
- Kiel Culbert certigis, ke li ne influis la intervjuitojn? Li povus demandi ilin letere antaŭ ol li parolis kun ili. En kelkaj regionoj li uzis kaj la unuan, profundan manieron kaj la duan, intervjuan manieron. Ĉu li tiam menciis al tiuj intervjuitoj ke li ankaŭ serĉis la tutan regionon? Pro tio tiuj intervjuitoj eble dirus pli verŝajnajn taksojn.
- Pere kelkaj eŭropaj regionoj, Culbert klarigis la rilaton inter la du manieroj de taksado en regiono. Estus pli bone, se li uzus malsimilajn regionojn, ĉar la rilato verŝajne dependas de la denseco de parolantoj.
Ankaŭ estas kelkaj suspektindaj aferoj
- Kial Culbert ne donis la datenaron al la publikon? Tio nur estus avantaĝo, se la datenaro havas problemojn.
- Kial Culbert nur menciis la nombron de parolantoj en la tuta mondo kaj ne la nombrojn de parolantoj en la diversaj partoj de la mondo? Kiam oni faras Partigita Hazarda Eltirado, oni ankaŭ taksas la nombrojn de parolantoj en ĉiu parto.
- Kial Culbert neniam menciis la konfidentan intervalon? En Partigita hazarda eltirado, la formulo estas tre simpla.
- Kial Culbert ne kunlaboris por kolekti datenojn? La kolektado devus esti tiom sistema, ke aliuloj povus fari tion.
Ni fakte ne scias multe pri la laboro de Culbert. Se ni suspektas la plej malbonan situacion, lia esploro ŝajnas havi gravajn erarojn. La fermita datenaro estas la plej grava kialo, kial vi devus suspekti tion. La takso estas 30-50 jaroj aĝa, do ĝi ne necese kontraŭdiras la nuntempajn taksojn bazite sur ŝtataj censoj. Tamen, estus strange se la nombro de parolantoj malkreskis per faktoro 10-20 dum tiuj jaroj. La takso de Culbert verŝajne estas nefidinda.
Kompari Esperanton kun aliaj lingvoj
La baza kalkulado estas

Ekzemple, la elekto Y=nombro de vikipediaj artikoloj, X=la angla, implikas(2017)

22 milionoj estas tro multe, kaj la problemo en la kalkulado estas, ke esperantistoj verkas pli da artikoloj po parolanto. La aro da parolantoj de Esperanto ĝenerale ne similas al aro da parolantoj de alia lingvo, ĉar
- Tre malgranda proporcio de la esperantaj parolantoj estas denaskaj
- Esperantaj parolantoj emas disvastigi la lingvon
- Esperanto estas pli ofte ŝatokupo kiu oni povas distingi sin
- Esperantaj parolantoj publikigas multon en Esperanto.
Bonaj elektoj plenumas, ke esperantistoj faras Y tiom ofte, kiom la parolantoj de X. Tial, la plejparto de la elektoj de X kaj Y estas malbona. Tamen estas unu tia takso, kiu estas estimata. Amri Wandel(2015) taksis, ke estas 2,000,000 parolantoj per Y=nombro de Facebook-uzantoj kiuj diras ke ili parolas Esperanton. Ethnologue referas tiun nombron en sia retejo. Wandel ne difinas esperanta parolanto, kaj uzas la anglan vorton, speaker. Sube estas la nombroj menciitaj de Wandel
| X: Kompara lingvo | Nombro de parolantoj | Nombro de parolantoj en FB | Frakcio |
|---|---|---|---|
| Franca | 190,000,000 | 42,000,000 | 0.22 |
| Germana | 200,000,000 | 23,000,000 | 0.12 |
| Hebrea | 9,000,000 | 1,300,000 | 0.14 |
| Esperanto | ? | 320,000 | ? |
| Klingona | ~20 | 250,000 | ~12500 |
Por plenumi la tabelon, Wandel unue argumentis per tre kuraĝaj supozoj pri ekzemple la nombro de homoj, kiuj malĝuste diras, ke ili parolas Esperanton sur Facebook. Li supozis ke tiu nombro estis 160,000(=320,000/2) sen pruvo aŭ plia argumento. Mi komentas ĉiun kuraĝan supozon en la apendikso. La kuraĝaj supozoj kaŭzas, ke la finfina takso estas 1,920,000, do la finfina frakcio inter parolantoj monde kaj parolantoj laŭ Facebook estas 0.15. Sekvante, Wandel argumentas, ke la frakciojn de la franca, germana kaj hebrea lingvo kongruas kun la frakcio 0.15.
Ambaŭ argumentoj de Wandel estas problemaj. Unue, la kuraĝaj supozoj de Wandel ne estas konvinkaj. Due, oni ne atendus, ke la esperanta frakcio egalas la aliajn frakciojn, ĉar la esperanta parolantaro ne similas al aliaj parolantaroj. Esperantaj parolantoj parolas pri Esperanto ofte, kial ili verŝajne mencias iliajn lingvojn pli ofte. Eble multaj homoj, kiuj ne parolas Esperanton, ŝatas Esperanton pro ĝia ideo. Tiaj homoj povus subteni Esperanton per postuli paroladon sur Facebook. Eble homoj ŝerce diras ke ili parolas Esperanton. La klingona lingvo sur Facebook estas ekstrema ekzemplo. Laŭ Facebook estas 250,000 klingonaj parolantoj kvankam nur estas 20-30 (laŭ vikipedio). Mi kredas, ke la esperanta frakcio devus esti ie inter la frakcioj de la ordinaraj lingvoj kaj la klingona frakcio.
Konklude, estas stranga, ke 320,000 esperantaj parolantoj en Facebook signifas 2,000,000 parolantoj monde.
Konkludo
Mi kunigis la LW-taksojn, kaj mi kunigis la JL-taksojn, do mi atingis la sekvantan liston. La koloroj montras la kvar kategoriojn.
| Metodo | Miloj da parolantoj |
|---|---|
| Z Dijk(2003) | <50 |
| S Nielsen(2016) | 62 |
| A Kück(2005) | 80 |
| J Lindstedt(1996) | 100 |
| J Lebl(2016) | 153 |
| L Wentsch(2009) | 230 |
| S Culbert(1989) | 2,000 |
| A Wandel(2015) | 2,000 |
La du plej grandaj taksoj ambaŭ havas gravajn problemojn – La metodo kaj datenaro de Culbert estas kaŝita kaj Wandel uzis nekonvinkajn argumentojn. Do 2,000,000 estas verŝajne tro granda. La ideo antaŭ la SVN-, JL-, AW- kaj LW-modeloj estas la samaj kaj baziĝas sur oficialaj, populaj censoj. Kvankam populaj censoj povus esti problema, ili estas la malpli malbona informo pri la nombro de esperantaj parolantoj. Inter la kvar metodoj, la SVN modelo uzas pli da datenoj, do ĝi devus esti pli preciza kvankam la konfidenta intervalo estas [31,183]. La taksoj de Lindstedt kaj Dijk nur estas divenoj sed kongruas kun la SVN takso.
Apendikso
En ĉi tiu sekcio mi priskribas tion, kio ne necesas en la ĉefa teksto, sed tamen estas interesa.
Kritiko de la rusa censo(2010)
Multaj esperantistoj dubis pri la rusa censo. Nur ekzistas anekdotaj signoj de fuŝado. Tamen, konkretaj pruvoj verŝajne ne ekzistus.



Analizo de la supozoj de Wandel
En ‘How Many People Speak Esperanto? Esperanto on the Web’(2015) Amri Wangel taksis ke estas du milionoj esperantistoj. Mi klarigas la metodon per difino kaj supozoj.
Difino
Esperantisto estas homo, kiu parolas Esperanton sufiĉe bone.
Supozoj
- Ĉiu esperantisto uzas la reton.
- La elcento de retuzantaj esperantistoj kiuj uzas Facebook egalas la elcenton de retuzantoj kiuj uzas Facebook.
- Triono de esperantistoj sur Facebook diras, ke ili parolas Esperanton sur Facebook.
- Duono de tiuj, kiuj dirus ke ili parolas Esperanton sur Facebook estas esperantistoj.
Datenaro
La datenaro konsistas el du nombroj
- 320,000 homoj diras ke ili parolas Esperanton sur Facebook.
- 25% de retuzantoj havas Facebook profilon.
Kalkulo
Laŭ supozo 1 kaj 2, sekvas
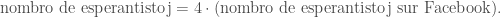
Laŭ supozo 3, sekvas

Laŭ supozo 4

Do
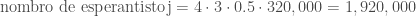
Miaj komentoj
- La difino:
- La elektita difino estas flua. Kia nivelo estas ‘paroli Esperanton sufiĉe bone’? Pro malklara difino, la rezulto estas preskaŭ nefalsebla.
- Supozo 1:
- Plejparto de esperantistoj verŝajne uzas la reton, kial ĉi tiu supozo estas bona.
- Supozo 2:
- Facebook estas populara en landoj, kiuj havas multe da esperantistoj. Ekzemple Ĉinio havas relative malmultajn esperantistojn, sed ĉinanoj tute ne uzas Facebook. La kaŭzita eraro povus esti faktoro 4 (se ĉiuj esperantisto havus Facebook profilon).
- Supozo 3:
- La kvanto 1/3 estas tre hazarda, kaj mi ne scias kiom la supozo pravas. La rezulto estas multiplikite per la kvanto, do la grandeco de la kvanto gravas multe.
- Supozo 4:
- Denove, la nombro 1/2 estas hazarda. Sed pli grava; la nombro de homoj, kiuj malvere diras ke ili parolas Esperanton, ne nature rilatas al la nombro de homoj, kiuj vere dias, ke ili parolas Esperanton. Kial 160,000 estas bona nombro de mensogintoj? Ĉu ne 280,000 ankaŭ ŝajnas verŝajna? Se la nombro de mensogintoj estis tiom granda, la takso estus
. Ni scias, ke la nombro estas maksimume 320,000, sed krom tio, ni ne scias multe.
- Denove, la nombro 1/2 estas hazarda. Sed pli grava; la nombro de homoj, kiuj malvere diras ke ili parolas Esperanton, ne nature rilatas al la nombro de homoj, kiuj vere dias, ke ili parolas Esperanton. Kial 160,000 estas bona nombro de mensogintoj? Ĉu ne 280,000 ankaŭ ŝajnas verŝajna? Se la nombro de mensogintoj estis tiom granda, la takso estus
Konklude, Wandel uzis gravajn nombrojn kiuj ne estis bazite sur dateno. Tial ni devus rigardi ĉi tiun supoz-metodon kvazaŭ diveno.
Finfine, se vi konas aliajn indajn taksojn, mi ŝatus pritakti ilin ĉi tie. Dankon al mia fratineto Signe Vendelbo Nielsen, kiu helpis min pri la teksto kaj desegnis la ĉefbildon.

Vidu informojn pri kalkulado de esperantistoj en http://www.facebook.com/groups/censo.epo
LikeLike
[…] [1] La plej freŝa, serioza kaj leginda artikolo pri la nombro de Esperantistoj en la mondo miaopinie estas tiu: Kalkulinda (Svend), La nombro de parolantoj de Esperanto en la mondo, 2018, rete legebla. […]
LikeLike
Tre interese, dankon! Efektive, miaj taksoj celis montri la dekumajn ŝtupojn kun marĝeno de duona ŝtupo, do 100 000 signifas “inter proksimume 30 mil kaj 300 mil”. – Jouko Lindstedt
LikeLike