
Plots
Takket være AJSP databasen fra Max Planck instituttet har jeg kunnet udføre udregningen i artiklerne af Müller og gruppe og lave efterfølgende plots med MDS-metoden(se metodesektion).

Diskussion
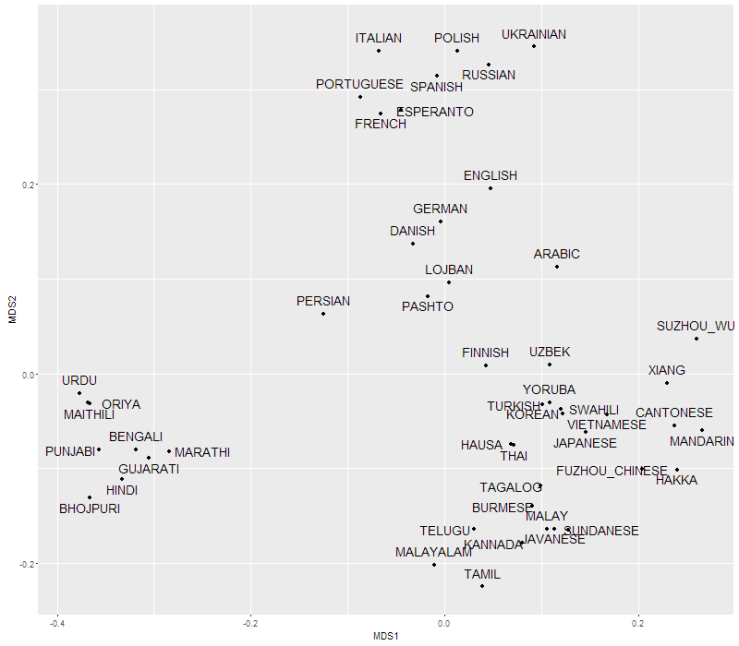
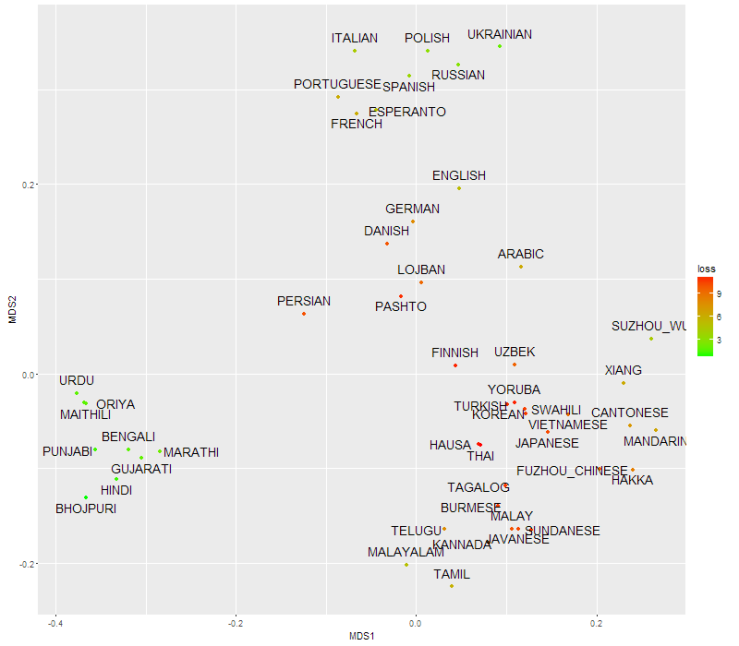
Med det valgte afstandsmål er der stor forskel mellem sprogene. Selvom distancematricen har visse store sproggrupper, er størstedelen af sprogene langt fra hinanden. Tilsvarende er der mange punkter i MDS-plottet som ikke passer godt ind. Der er simpelthen ikke plads til, at alle sprogene kan være på en todimensionel flade, uden at de ligger for tæt eller for spredt. Sprog repræsenteres altså bedre i et højdimensionalt rum.
Lojban og Esperanto
Det er nemmest at lære sprog, som er nærmest ens modersmål(Isphording, I.E. and Otten, S., 2011), hvilket heldigvis giver os danskere nem adgang til verdens vigtigste sprog, engelsk. Esperanto, som jeg agiterede for i sidste post, er et let sprog, som er lavet for at flere skal have nem adgang til et fælles sprog. Esperanto bliver dog ofte beskyldt for at være europæisk. Som kandiderende globalt sprog bør det ikke tilhøre en bestemt sproggruppe, siges det. Esperanto er tydeligvis et europæisk sprog, men hvad er alternativet? Når sprog befinder sig i et mangedimensionelt rum, er en sammenblanding af alle sprog langt væk fra alle sprog. Det illustreres af lojban, der blev udregnet i 1987 baseret på de seks sprog mandarin, engelsk, spansk, hindi, arabisk og russisk. Lojban bliver placeret i midten af MDS-plottet, og bliver lige akkurat klassificeret ind i den europæiske del af phylogenien. Dog er lojbans afstande til alle andre sprog forholdsvis stor ifølge distancematricen. Den ligger kun i midten af MDS-plottet, fordi ingen andre sprog kan nærme sig den. Med dette afstandsmål er lojban lige så svært for alle, som esperanto er for ikke-europæere.
Metoder
Swadeshlisten er en liste af 100 menneskelige begreber som jeg, hvem, bjerg, høre, stor og så videre. Listen bruges til at sammenligne forskellige sprog ved at betragte deres oversættelser af begreberne. Efter listens skabelse er den først blevet udvidet til 207 ord med formål at øge den statistiske slagkraft, for så at blive reduceret til de 40 ord, som bærer mest af denne slagkraft. (Hvilket for mig lyder som om, man i stedet skulle lave en bedre statistisk model, men det tænker jeg alligevel så tit).
Max Planck instituttet har lavet databasen AJSP med Swadeshlisten for over 7000 sprog. Alle oversættelser er udtrykt i det samme fonetiske alfabet, hvilket gør det muligt at gå systematisk til værks. Müller og medhjælpere brugte databasen på følgende måde:
- Afstanden mellem to ord defineres til at være den normaliserede Levenshteindistance(LDND).
- Levenshteindistancen(LD) er det mindste antal operationer der skal til at for at forvandle det ene ord til det andet.
- En operation er enten at udskifte et bogstav, fjerne et bogstav eller indsætte et bogstav.
- Normaliseringen gøres i 2 skridt
- Dividere afstanden LD med den største længde af de to ord. Dette giver LDN.
- Dividere LDN med den gennemsnitlige LDN af andre ord mellem de to sprog. Dette giver LDND.
- Levenshteindistancen(LD) er det mindste antal operationer der skal til at for at forvandle det ene ord til det andet.
- Afstanden mellem to sprog defineres til at være den gennemsnitlige afstand mellem ordene på Swadeshlisten fra de to sprog.
- Parvise afstande mellem alle sprog laver en phylogeni over alle sprog ved hjælp af Neighbour joining.
- En phylogeni angiver den evolutionære struktur mellem elementer, som her er Mand, abe og mus:
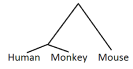
- En phylogeni angiver den evolutionære struktur mellem elementer, som her er Mand, abe og mus:
Jeg vil i store træk genskabe Müllergruppens fremgangsmåde og resultater, men for at kunne lave et pænt ‘kort’ over verdens sprog, tager jeg nogle andre valg:
- Afstanden mellem to ord defineres til at være den normaliserede Levenshteindistance(
LDNDLDN).- Levenshteindistancen(LD) er det mindste antal operationer der skal til at for at forvandle det ene ord til det andet.
- En operation er enten at udskifte et bogstav, fjerne et bogstav eller indsætte et bogstav.
- Normaliseringen gøres i
21 skridt- Dividere afstanden LD med den største længde af de to ord. Dette giver LDN.
Dividere LDN med den gennemsnitlige LDN af andre ord mellem de to sprog. Dette giver LDND.
- Levenshteindistancen(LD) er det mindste antal operationer der skal til at for at forvandle det ene ord til det andet.
- Afstanden mellem to sprog defineres til at være den gennemsnitlige afstand mellem ordene på Swadeshlisten fra de to sprog.
- Parvise afstande mellem
allenogle sprog laver en phylogeni overallenogle sprog ved hjælp af Neighbour joining.- En phylogeni angiver den evolutionære struktur mellem elementer, som her er Mand, abe og mus:
- En phylogeni angiver den evolutionære struktur mellem elementer, som her er Mand, abe og mus:
- Parvise afstande mellem nogle sprog laver et ‘kort’ over verdens sprog ved hjælp af Multidimensional scaling(MDS).
- Multidiemnsional scaling transformerer parvise afstande til punkter i et n-dimensionalt plan. Forestil, at vi kun kendte alle indbyrdes afstande mellem byer i Danmark og ikke byernes faktiske placering. Da ville multidimensional scaling(med n=2) kunne give et godt bud på Danmarkskortet ud fra afstandene. Mere teknisk fungerer MDS ved at minimere forskellene mellem de faktiske byafstande og afstandene på det estimerede kort.
- Jeg plotter distancematricen.
- distancematricen angiver i rækken hørende til et bestemt sprog afstandene mellem dette sprog og alle de andre sprog.
Jeg bruger ikke LDND, fordi den er mærkelig, og resultaterne ser fine ud med LDN. Jeg bruger kun en delmængde af sprogene, da jeg kun vil have et plot over de største sprog. Jeg har taget de 45 sprog, som flest taler som modersmål samt mine yndlings-/hadesprog dansk, esperanto, lojban og finsk. For ikke at lade MDS-plottet påvirkes af mine arbitrære valg af yndlingssprog, har jeg vægtet yndlingssprogene ubetydelige.
Data kan downloades via AJSP hjemmesiden (for at gøre præcis som jeg har gjort, skal man hente zip-filen Dataset in CLDF [10.9MB]). Koden er på Github i det nye, smarte RStudio Notebook-format.
